Positive Deviance:
A Data-Powered Approach to the Covid-19 Response
June 9, 2020
Richard Heeks and Basma Albanna, Centre for Digital Development, University of Manchester
This blog post was written by our partners from the Centre for Digital Development at the University of Manchester and was first published on the initiative's Medium Blog.
Positive Deviance and Covid-19
Nations around the world are struggling with their response to the Covid-19 pandemic. In particular, they seek guidance on what works best in terms of preventive measures, treatments, and public health, economic and other policies. Can we use the novel approach of data-powered positive deviance to improve the guidance being offered?
Positive deviants are those in a population that significantly outperform their peers. While the terminology of positive deviance is absent from public discourse on Covid-19, the concept is implicitly present at least at the level of nations. In an evolving list, countries like New Zealand, Australia, Taiwan, South Korea and Germany regularly appear among those seen as most “successful” in terms of their relative infection or death rates so far.
Here we argue first that the ideas and techniques of positive deviance could usefully be called on more directly; second that application of PD is probably more useful at levels other than the nation state. In the table below, we summarise four levels at which PD could be applied, giving potential examples and also potential explanators: the factors that underpin the outperformance of positive deviants.

At present, items in the table are hypothetical and/or illustrative but they show the significant value that could be derived from identification of positive deviants and their explanators. Those explanators that are under social control — such as use of technological solutions or policy/managerial measures — can be rapidly scaled across populations. Those explanators such as genetics or pre-existing levels of healthcare capacity which are not under social control can be built into policy responses; for example in customising responses to particular groups or locations.
Evidence from positive deviance analysis can help currently in designing policies and specific interventions to help stem infection and death rates. Soon it will be able to help design more-effective lockdown exit strategies as these start to show differential results, and as post-lockdown positive deviants start to appear.
However, positive deviance consists of two elements; not just outperformance but outperformance of peers. It is the “peers” element that confounds the value of positive deviance at the nation-state level.
Public discourse has focused mainly on supposedly outperforming nations; yet countries are complex systems that make meaningful comparisons very difficult: dataset definitions are different (e.g. how countries count deaths); dataset accuracy is different (with some countries suspected of artificially suppressing death rates from Covid-19); population profiles and densities are different (countries with young, rural populations differing from those with old, urban populations); climates are different (which may or may not have an impact); health service capacities are different; pre-existing health condition profiles are different; testing methods are different; and so on. Within all this, there is a great danger of apophenia: the mistaken identification of “patterns” in the data that are either not actually present or which are just random.
More valid and hence more useful will be application of positive deviance at lower levels. Indeed, the lower the level, the more feasible it becomes to identify and control for dimensions of difference and to then cluster data into true peer groups within which positive deviants — and perhaps also some of their explanators — can then be identified.
Data-Powered Positive Deviance and Covid-19
The traditional approach to identifying positive deviants has been the field survey: going out into human populations (positive deviants have historically been understood only as individuals or families) and asking questions of hundreds or thousands of respondents. Not only was this time-consuming and costly but it also becomes more risky or more difficult or even impractical during a pandemic.
Much better, then, is to look at analysis of large-scale datasets which may be big data and/or open data, since this offers many potential benefits compared to the traditional approach. Many such datasets already exist online, while others may be accessed as they are created by national statistical or public health authorities.
Analytical techniques, such as those being developed by the Data Powered Positive Deviance initiative, can then be applied: clustering the data into peer groups, defining the level of outperformance needed to be classified as a positive deviant, identifying the positive deviants, then interrogating the dataset further to see if any PD explanators can be extracted from it.
An example already underway is clustering the 401 districts in Germany based on data from the country’s Landatlas dataset and identifying those which are outperforming in terms of spread of the virus. Retrospective regression analysis is already suggesting structural factors that may be of importance in positive deviant districts: extent and nature of health infrastructure including family doctors and pharmacies, population density, and levels of higher education and of unemployment.
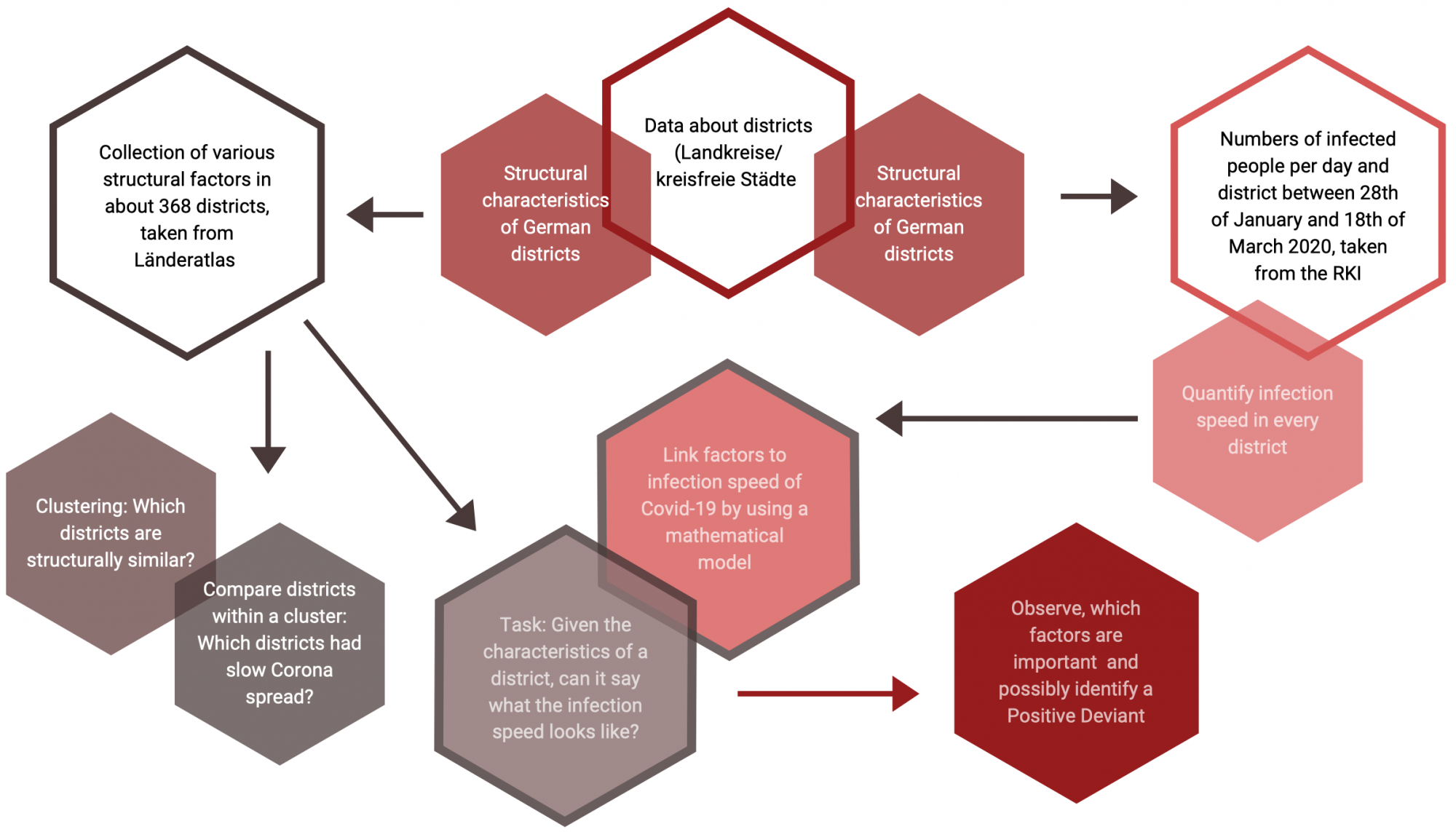
This can then be complemented in two directions — diving deeper into the data via machine learning to try to predict future spread of the disease; and complementing this large-scale open data with “thick data” using online survey and other methods to identify the non-structural factors that may underlie outperformance. The latter particularly will look for factors under socio-political control such as policies on lockdown, testing, etc.
Of course, great care must be taken here. Even setting aside deliberate under-reporting, accuracy of the most basic measures — cases of, and deaths from Covid-19 — has some inherent uncertainties. Beyond accuracy are the broader issues of “data justice” as it applies to Covid-19-related analysis, including:
- Representation: the issue of who is and is not represented on datasets. Poorer countries, poorer populations, ethnic minority populations are often under-represented. If not accounted for, data analysis may not only be inaccurate but also unjust.
- Privacy: arguments about the benefits of analysing data are being used to push out the boundaries of what is seen as acceptable data privacy; opening the possibility of greater state surveillance of populations. As Privacy International notes, any boundary-pushing “must be temorary, necessary, and proportionate”.
- Access and Ownership: best practice would seem to be datasets that are publicly-owned and open-access with analysis that is transparently explained. The danger is that private interests seek to sequester the value of Covid-19-related data or its analysis.
- Inequality: the key systems of relevance to any Covid-19 response are the economic and public health systems. These contain structural inequalities that benefit some more than others. Unless data-driven responses take this into account, those responses may further exacerbate existing social fracture lines.
However, if these challenges can be navigated, then the potential of data-powered positive deviance can be effectively harnessed in the fight against Covid-19. By identifying Covid-19 positive deviants, we can spotlight the places, institutions and people who are dealing best with the pandemic. By identifying PD explanators, we can understand what constitutes best practice in terms of prevention and treatment; from public health to direct healthcare. By scaling out those PD explanators within peer groups, we can ensure a much-broader application of best practice which should reduce infections and save lives. And using the power of digital datasets and data analytics, we can do this in a cost- and time-effective manner.