Unveiling Vulnerabilities in Climate Policy: AI Tools for Insights into Climate Policy Inclusivity
March 14, 2024
Lea Voigt, Robin Nowok, Erik Lehmann, Mark Tyrrell

The consequences of the climate crisis are affecting people across the world, but it is well-known that people in vulnerable situations (due to factors including but not limited to age, gender, geography, health or indigenous or minority status) may experience heightened exposure and are disproportionately more affected than other demographic groups.
When signing the 2015 Paris Agreement, countries committed to taking this differential exposure into account and considering groups in vulnerable situations when integrating adaptation into relevant socioeconomic and environmental policies and actions, where appropriate (Article 7.5). These considerations are commonly mirrored in governments’ climate policy documents such as the Nationally Determined Contributions (NDCs). However, while the information is out there, it proves difficult gaining a complete understanding to what extent different groups are considered in each country’s climate policy since manually going through the documents and identifying references to different groups can be time- and resource-intensive. For instance, details relevant to a specific demographic group may be embedded in sections of text or entire documents that defy expectations based on their titles or prominent keywords. In addition, it also appears occasionally that documents are saved as scans and not as PDFs or similar, meaning that the user does not even have the option of scanning the document for keywords. This complexity shows the need for advanced analytical tools and methodologies to ensure a comprehensive examination of climate policies and their inclusivity across diverse societal segments.
To address this knowledge gap, we prototyped the use of AI for a systematic review of references and tangible actions related to groups in vulnerable situations in climate policy documents. The results are two apps that provide easy access to summarized information of references and actions related to different groups in vulnerable situations. The use case was initiated together with our colleagues from the NDC Assist programme of GIZ Kenya and the CRAWN Trust and implemented together with Mark Tyrrell from GFA.
Defining groups in vulnerable situations
In our pursuit to understand climate vulnerabilities, we initially focused on women, children, and youth. Recognizing the need for a broader perspective, we shifted towards an intersectional approach but found no existing taxonomy that matched our comprehensive vision. Therefore, we drew on insights from the GIZ led sector program on human rights and our policy analysis experiences to create a new taxonomy.
This framework incorporates gender, age, socio-economic status, occupation, health, and geographical factors to capture the nuanced ways these elements interact and influence vulnerabilities to climate change. This intersectional taxonomy is important to our project, enhancing our understanding of the complex challenges diverse groups face due to climate change. The following groups have been defined:
Training the AI Classifier
To make predictions on whether a certain paragraph includes a reference to one of the vulnerable groups mentioned above, we have created our own training dataset to fine-tune a pre-trained sentence transformer model (i.e., deep learning model designed for encoding and transforming sentences or text paragraphs into fixed-dimensional vectors). To fine-tune the pre-trained model on our training data, we used SetFit, an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers. The benefit of SetFit is that it achieves high accuracy with very few data points per class and therefore works well with smaller datasets.
The first iteration of training data was collected manually by a team of four colleagues and consisted of paragraphs referring to the different groups, taken from climate policy or similar documents. Collecting the first round by hand helped to ensure the quality of the training data. We started by collecting 10 paragraphs for each group.
To increase the performance of the model, the dataset has later been extended to at least 20 examples per group and to be multilabel (i.e., multiple groups can be mentioned in the same paragraph), leading to a final dataset of 475 paragraphs. Rather than starting from scratch, we relied on 'active learning', using the first version of the fine-tuned model to predict whether paragraphs from climate documents referred to different groups, and then annotating a certain number of paragraphs that were predicted to refer to a particular group. In addition to labelling whether the paragraphs contain a reference to a vulnerable group, we also checked whether the reference is a concrete action/target or just a general reference.
After the second-round of fine-tuning, the performance of the model increased further. However, one should note that the performance varies between the different classes. For example, the model performs well for references related to “Women and other gender” and “Children”, correctly classifying our hold-out test examples in 93% / 89% (F1-Score) of the cases, but does not work as well for e.g., “Persons with disabilities”, where it only recognizes 44% (F1-Score) of the cases. The class relating to “Persons with pre-existing health conditions” is the only class that does not perform well at all. This is something that could be improved by sharpening the framework and collecting more training data when further developing the prototype. The full model report and the performance of each class can be seen below.
Using Generative AI to make the information accessible
Identifying references to groups in vulnerable situations and policy actions is a first important step. However, instead of simply providing a list of paragraphs, we aimed to make the information even more accessible, using Generative AI and summarization techniques.
Our first prototype is an app that allows users to interact with different climate policy documents by simply asking a desired question. For example, one could ask “Which concrete actions are proposed in Kenya’s climate policy documents to support women?”. The user will then receive an AI-generated reply to that question, created by ChatGPT (3.5). Crucially, to avoid hallucinations commonly seen with generative AI, the app uses a technique called “retrieval-augmented generation (RAG)”, where the climate policy documents are first split in paragraphs and the abovementioned model is used to predict whether each paragraph contains a reference to one or several groups. The generative model (here ChatGPT) receives the text and predictions as input and only answers the question based on the analysis provided. Currently, the underlying document store available for query is limited to 10 Southern African countries (Angola, Botswana, Eswatini, Lesotho, Malawi, Mozambique, Namibia, South Africa, Zambia, Zimbabwe), as well as Kenya. This app prototype can be found here.
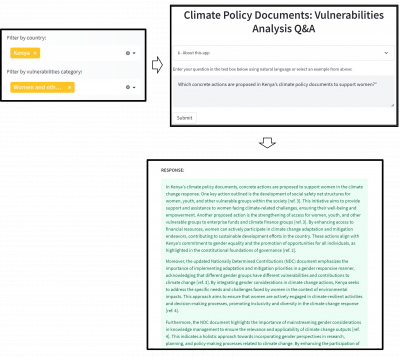
After receiving user feedback that it would be helpful to be able to upload your own documents of interest, instead of relying on a fixed underlying document store, we created a second version which allows the user to upload a document and receive a summary of the references for each group detected (including scanned documents, realized through methods of optical character recognition). For that, we make use of a technique called “Classification Augmented Summarization”. Similar to the RAG-pipeline, in a first step the document is being split in paragraphs, which are then classified by the trained model on whether they contain one or multiple reference to a group. However, then this information is fed into ChatGPT 3.5 with a specific prompt to summarize only activities relating to vulnerability of climate change. The summaries are provided to the user in the app interface. The latest version can be found here.

The result: Analyse documents with the push of a button
The results of our use case are two apps that use the power of (generative) AI to make information on groups in vulnerable situations from climate policy documents easily accessible to everyone and allow for a broader scale analysis. We hope that this will bridge the knowledge gap that persists when talking about groups in vulnerable situations, especially in the climate context. Overall, the prototype is a good inspiration for how AI and NLP techniques can be used for good in the field of development cooperation.
A cooperation between GIZ Data Lab, Data Service Center and our external partner GFA Consulting Group.