GIZ Data Lab
... brings together practitioners and creatives to promote the effective, fair, and responsible use of digital data for sustainable developmentWhat we Do
➜ Applying tried-and-true methods and imaginative outside-the-box thinking, we explore new data-related trends and develop multifaceted, forward-looking solutions to some of the most pressing development issues facing GIZ partner countries.
➜ Discover our approaches, learn from our successes, and get inspired.
➜ Join us in Working Out Loud, where we share early concepts, experimental ideas, and ongoing projects.
➜ Your feedback helps shape our work as we explore key focus areas and emerging priorities.
Data Lab Blog
Dive into our Data Lab Blog for in-depth explorations of AI-driven policy tools, data feminism, and sustainable solutions tackling global challenges




Topics
Data Feminism
Data Powered Positive Deviance
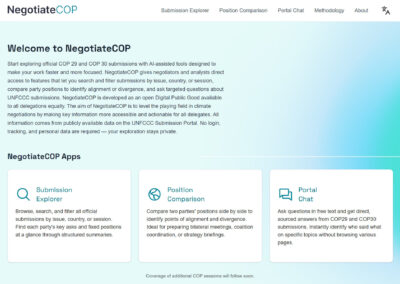
AI in Negotiations
Data for Development
About us
Founded in January 2019 as part of the Sectoral Department, the GIZ Data Lab works on behalf of the Deutsche Gesellschaft für Internationale Zusammenarbeit GmbH (GIZ) to harness the benefits of new data sources and data-related technologies.





Working Out Loud

